CAAPP Hardware
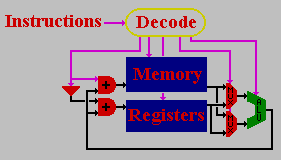
The CAAPP or Content Addressable Array Parallel Processor is a massively parallel SIMD processor composed of many simple processors (PEs).
The CAAPP hardware is constructed from multiple CAAPP chips, each a VLSI chip containing 256 simple processors.
The processors on a single chip are arranged in a 16 x 16 grid.
The chips are then arranged in a 4 x 4 grid in a quadnode.
The quadnodes are assembled into larger grids.
Possible sizes available for the CAAPP layer of an IUA go from 64 x 32 PEs to 128 x 128 PEs.
Each processor executes the same instruction as every other CAAPP processor.
Each CAAPP instruction takes one cycle.
Each processor has
- a simple, bit-serial ALU
- X, Y, A, and B single bit registers
- two 4-bit registers.
- four-way connected mesh network
- the Coterie network
- 320 bits of bit-addressable memory
- 16,384 bytes of off-chip, byte-addressable memory
The ALU is capable of doing single bit operations such as or, and,
xor, and add-with-carry.
A single instruction can reference
- two register operands and a destination register,
- two register operands and a memory destination,
- one register operand, one memory operand, and a register destination,
- one register operand, one memory operand, and the same memory location as a destination,
- one memory operand, the same memory location as the second operand, and a register destination, and
- one memory operand, the same memory location as the second operand, and the same memory location as a destination.
See instructions for details of the instruction set.
- X
- The X register is a single bit register which may be used as the source and destination of ALU operations.
In addition, the X register is used in global response operations.
- Y
- The Y register is a single bit register which may be used as the source and destination of ALU operations.
- B
- The B register is a single bit register which may be used as the source and destination of ALU operations.
- A
- The A register is a single bit register which may be used as the source and destination of ALU operations.
However, the main use of the A register is to control activity.
- MR
- The MR register is a four bit register that is used to control the coterie network and for 4-bit data transfers.
- SB
- The SB register is a four bit register that is used to control the coterie network and for 8-bit data transfers in conjunction with the MR register.
- BSR
- The 32-bit BSR register is used for off-chip data transfer as a buffer.
Since every processor executes the same instruction, conditional execution must be handled without changing the instruction sequence in a processor (branching).
Instead, control is exercised via conditional execution.
The result of a particular instruction generated by a specific PE is either written to the destination or not.
This is under control of the A register and bits set in the CAAPP instruction.
If the A register associated with a particular PE contains a one and the instruction specifies that activity is enabled, the result of the instruction will be written to the destination.
Otherwise, the destination will remain unchanged at that PE.
If activity is not enabled by an instruction, then every PE writes its results to the destination.
It is possible for a user's program to answer two questions concerning the entire array of processors in the CAAPP:
- Is there any PE that has a one in the X register?
- How many PEs have a one in the X register?
By placing a one or a zero in the X register of each PE, an instruction may be executed that returns the ORed value of all the X registers.
A similar instruction may be used to count all the ones in all the X registers.
These values are returned to the program executing on the ACU that controls the CAAPP.
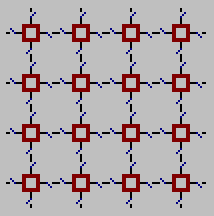
The mesh network provides a simple West, North, East, and South interconnect of each PE with its neighbor.
The network is connected in a torus so that PEs at the end of a row or column communicate with the PE at the other end.
A single instruction is used to access a single bit from the memory of the neighboring PE.
The effect is to shift the array of bits one position in the indicated direction.
The Coterie network provides a method of performing operations on regions of an image in parallel.
The PEs are four-connected to their neighbors with each PE having a switch that it can control to open or close the connection with a neighbor in a direction.
A segmentation is performed on the data which places each PE in one of several equivalence classes.
For example, all PEs whose value of a variable is between 5 and 8 may be placed in one equivalence class.
Then, each PE compares its class to its neighbor's class in each of the four directions using the mesh network.
If its class is the same, it closes a switch between it and its neighbor.
Once the regions have been formed, it is possible to broadcast a single bit on the network.
Each PE may place a bit on the network.
Each PE may read the value of the network.
The value of the network in a region is the logical OR of the bits placed on it in that region.
With this mechanism, it is possible to answer the question ``Did any PE in a region place a one on the network''?
If only one PE in each region places a value on the network, that value is broadcast to every other PE in the region.
This mechanism can be used to broadcast values from the master PE of a region to every other PE in the same region.
These operations can be used to compose higher-order operations.
To see this in action, press Movie.
In this movie, a portion of the CAAPP coterie network is shown.
At the beginning, the switches for each PE are open.
Then, the equivalence class values are shown (in color) for each PE.
The switches are then set appropriately in the next frame.
A master PE is then selected.
This is followed by frames showing the value broadcast by the master PE propagating to the other PEs in the region.
IUA Documentation
IUA Glossary
IUA Software
IUA Home Page
IUA Outline